.. meta::
:google-site-verification: S66K6GAclKw1RroxU0Rka_2d1LZFVe27M0gRneEsIVI
.. important::
.. raw:: html
bigdl-llm has now become ipex-llm, and our future development will move to the IPEX-LLM project.
################################################
The BigDL Project
################################################
************************************************
BigDL-LLM
************************************************
.. raw:: html
bigdl-llm is a library for running LLM (large language model) on Intel XPU (from Laptop to GPU to Cloud) using INT4/FP4/INT8/FP8 with very low latency [1] (for any PyTorch model).
.. note::
It is built on top of the excellent work of `llama.cpp `_, `gptq `_, `bitsandbytes `_, `qlora `_, etc.
============================================
Latest update 🔥
============================================
- [2024/03] 🔔🔔🔔 ``bigdl-llm`` **has now become** `ipex-llm `_; see the migration guide `here `_.
- [2024/03] **LangChain** added support for ``bigdl-llm``; see the details `here `_.
- [2024/02] ``bigdl-llm`` now supports directly loading model from `ModelScope `_ (`魔搭 `_).
- [2024/02] ``bigdl-llm`` added inital **INT2** support (based on llama.cpp `IQ2 `_ mechanism), which makes it possible to run large-size LLM (e.g., Mixtral-8x7B) on Intel GPU with 16GB VRAM.
- [2024/02] Users can now use ``bigdl-llm`` through `Text-Generation-WebUI `_ GUI.
- [2024/02] ``bigdl-llm`` now supports `Self-Speculative Decoding `_, which in practice brings **~30% speedup** for FP16 and BF16 inference latency on Intel `GPU `_ and `CPU `_ respectively.
- [2024/02] ``bigdl-llm`` now supports a comprehensive list of LLM finetuning on Intel GPU (including `LoRA `_, `QLoRA `_, `DPO `_, `QA-LoRA `_ and `ReLoRA `_).
- [2024/01] Using ``bigdl-llm`` `QLoRA `_, we managed to finetune LLaMA2-7B in **21 minutes** and LLaMA2-70B in **3.14 hours** on 8 Intel Max 1550 GPU for `Standford-Alpaca `_ (see the blog `here `_).
- [2023/12] ``bigdl-llm`` now supports `ReLoRA `_ (see `"ReLoRA: High-Rank Training Through Low-Rank Updates" `_).
- [2023/12] ``bigdl-llm`` now supports `Mixtral-8x7B `_ on both Intel `GPU `_ and `CPU `_.
- [2023/12] ``bigdl-llm`` now supports `QA-LoRA `_ (see `"QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models" `_).
- [2023/12] ``bigdl-llm`` now supports `FP8 and FP4 inference `_ on Intel **GPU**.
- [2023/11] Initial support for directly loading `GGUF `_, `AWQ `_ and `GPTQ `_ models in to ``bigdl-llm`` is available.
- [2023/11] ``bigdl-llm`` now supports `vLLM continuous batching `_ on both Intel `GPU `_ and `CPU `_.
- [2023/10] ``bigdl-llm`` now supports `QLoRA finetuning `_ on both Intel `GPU `_ and `CPU `_.
- [2023/10] ``bigdl-llm`` now supports `FastChat serving `_ on on both Intel CPU and GPU.
- [2023/09] ``bigdl-llm`` now supports `Intel GPU `_ (including Arc, Flex and MAX)
- [2023/09] ``bigdl-llm`` `tutorial `_ is released.
- Over 30 models have been verified on ``bigdl-llm``, including *LLaMA/LLaMA2, ChatGLM2/ChatGLM3, Mistral, Falcon, MPT, LLaVA, WizardCoder, Dolly, Whisper, Baichuan/Baichuan2, InternLM, Skywork, QWen/Qwen-VL, Aquila, MOSS* and more; see the complete list `here `_.
============================================
``bigdl-llm`` demos
============================================
See the **optimized performance** of ``chatglm2-6b`` and ``llama-2-13b-chat`` models on 12th Gen Intel Core CPU and Intel Arc GPU below.
.. raw:: html
| 12th Gen Intel Core CPU |
Intel Arc GPU |
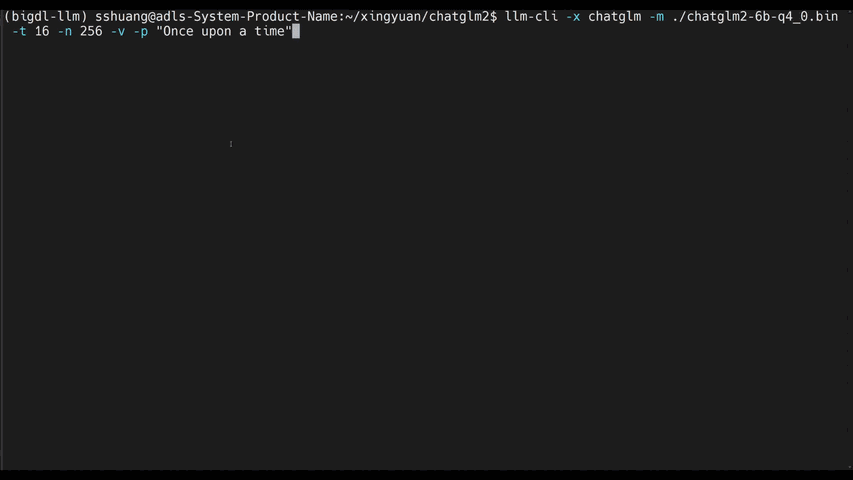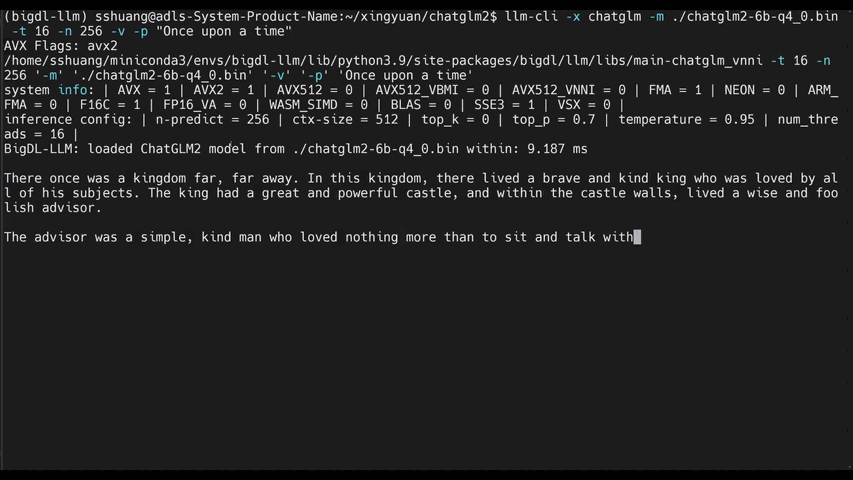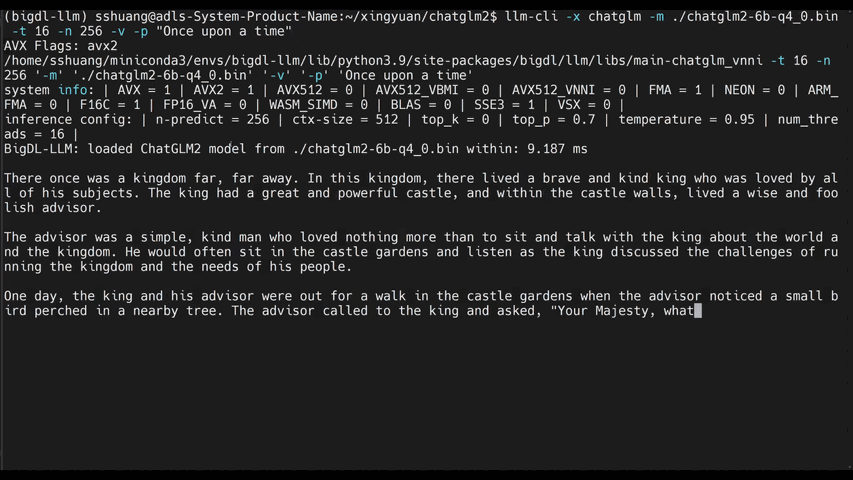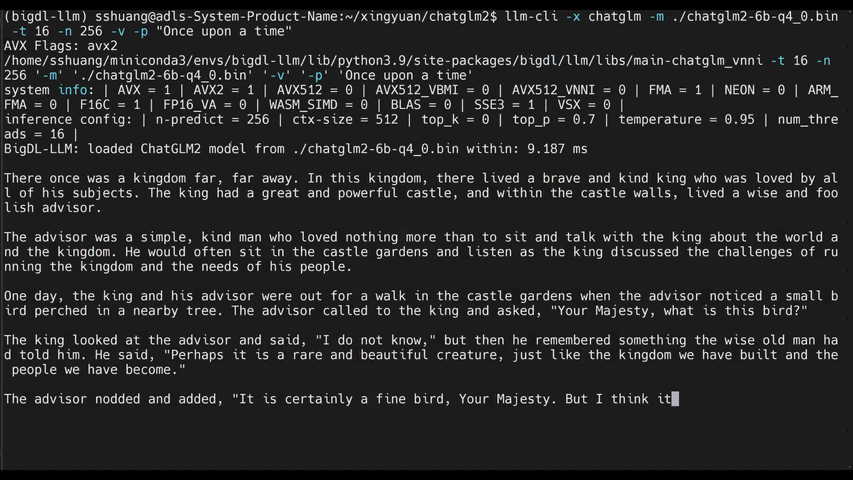
|
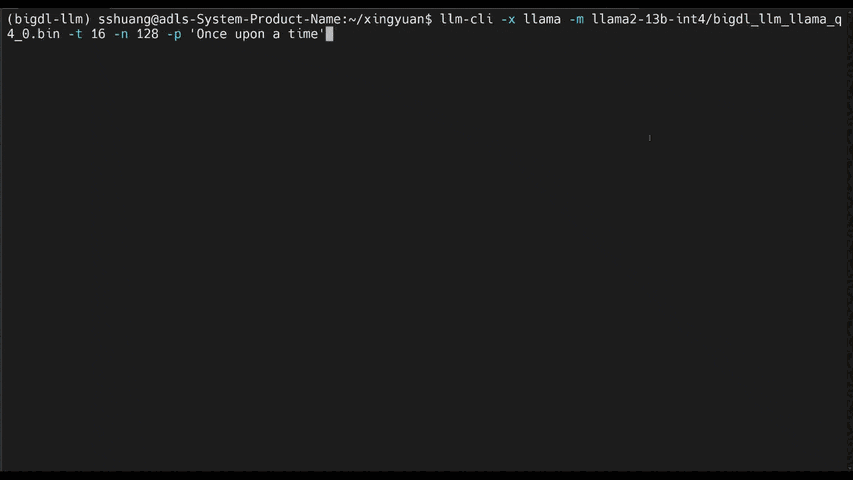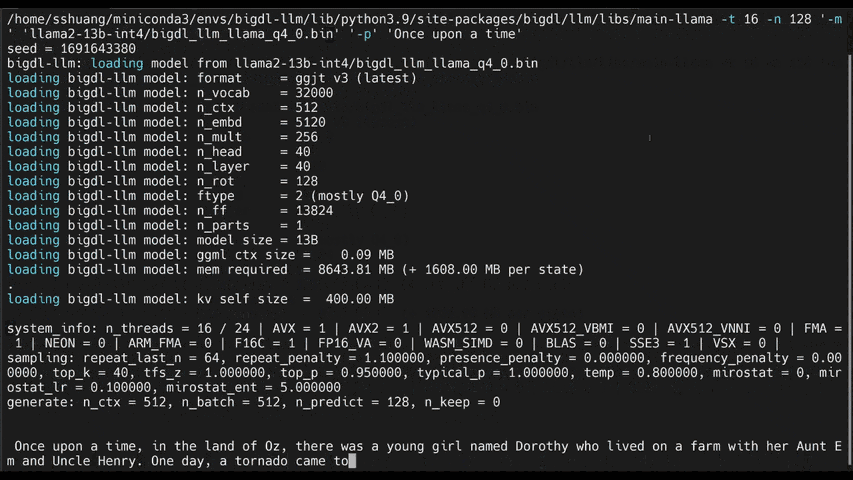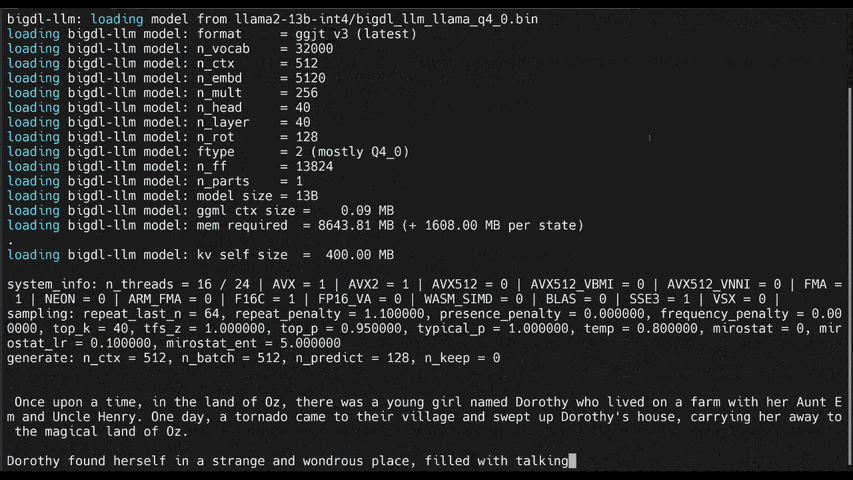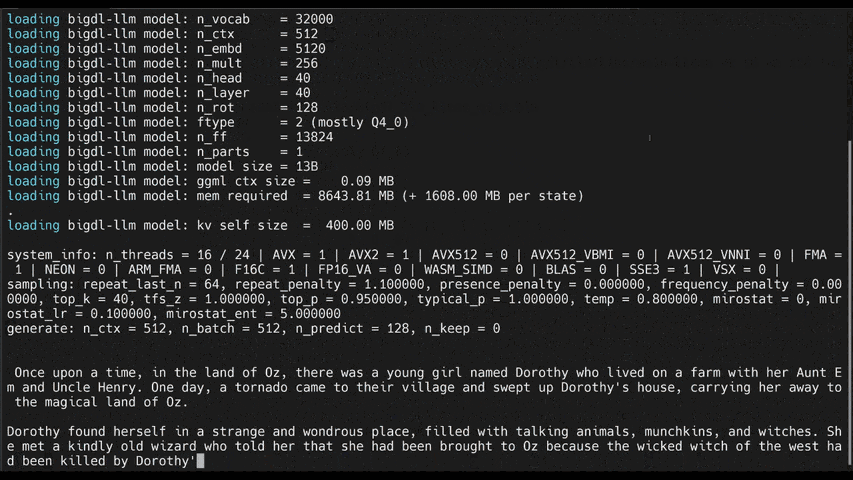
|
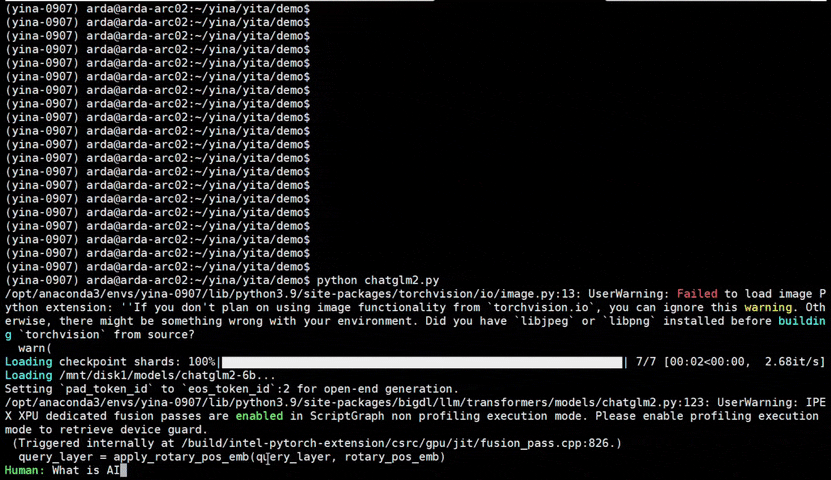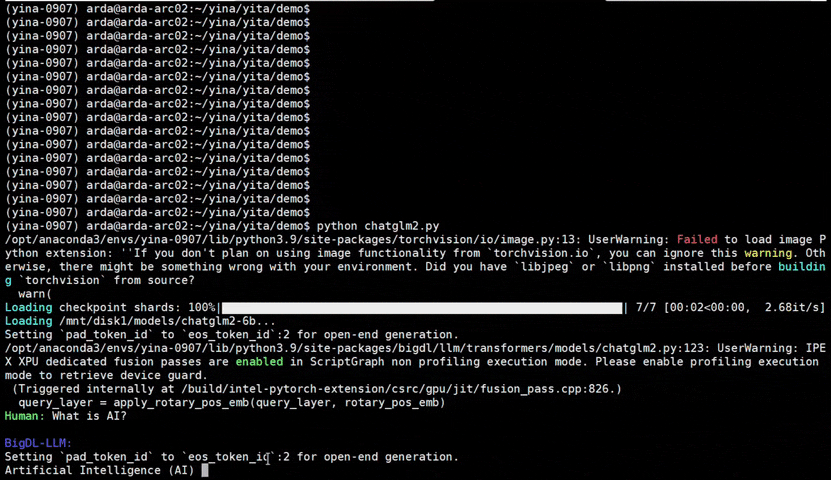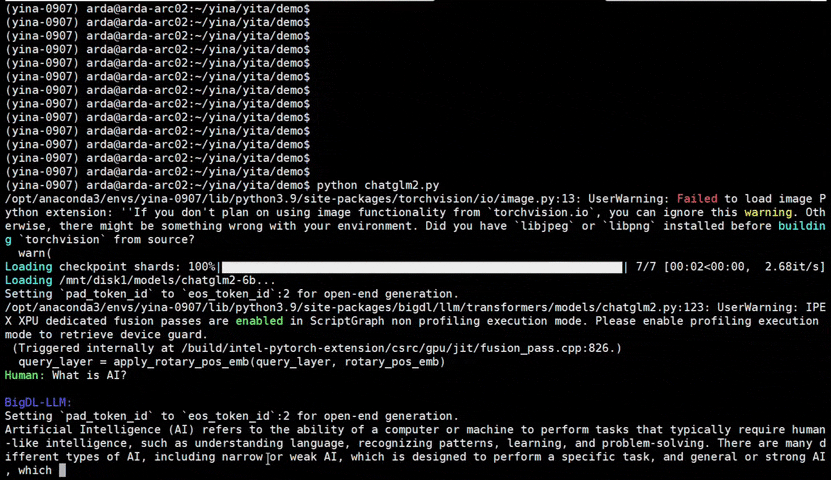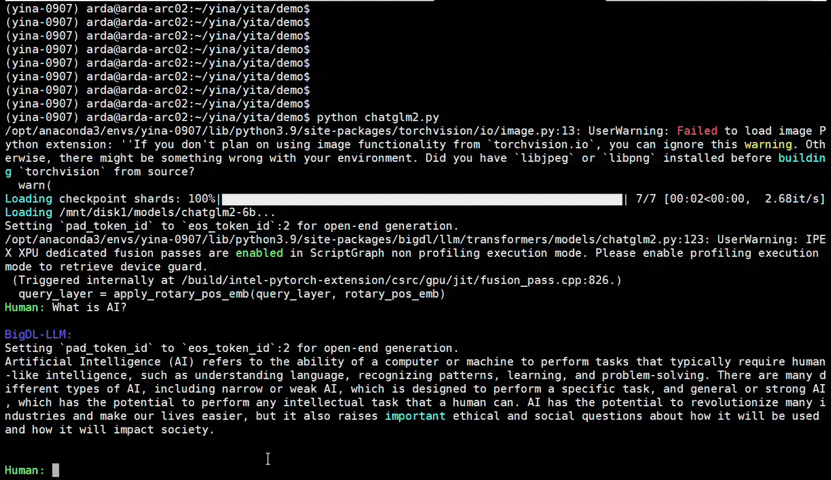
|
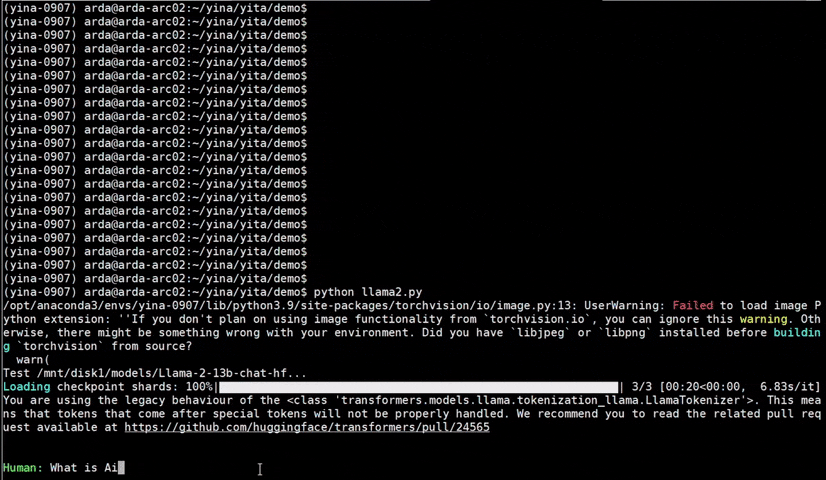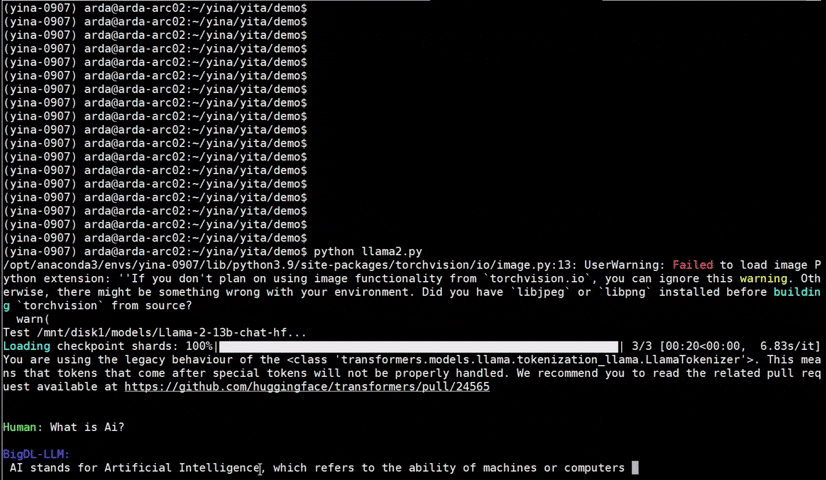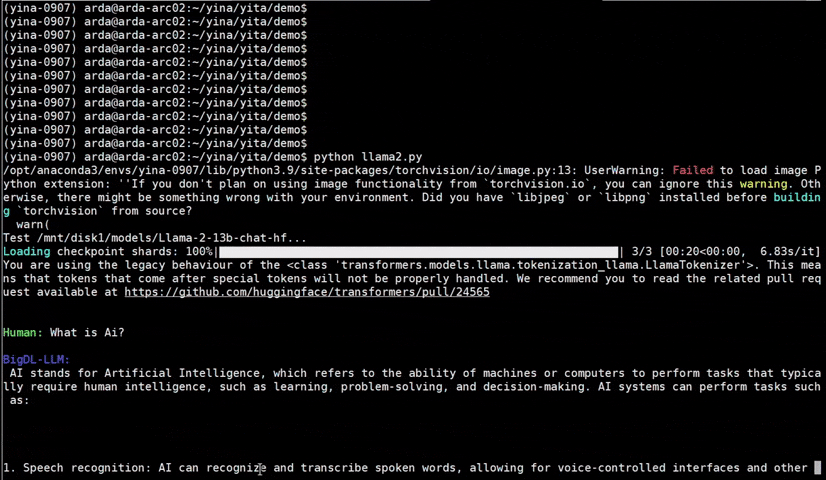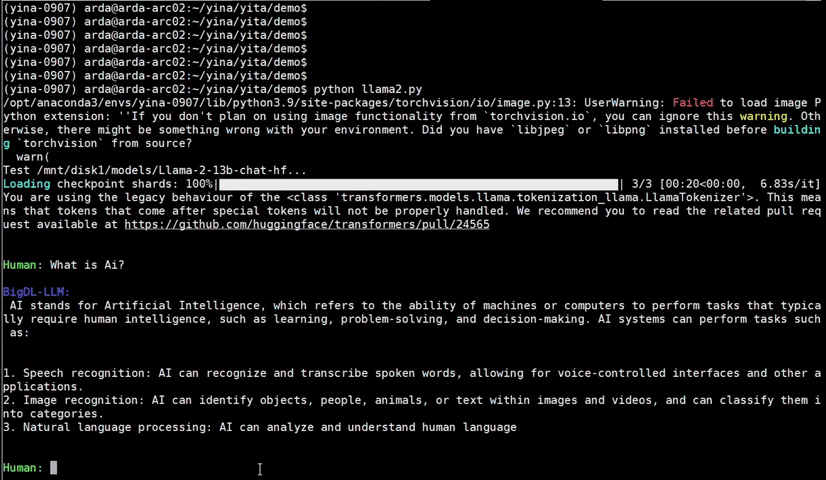
|
chatglm2-6b |
llama-2-13b-chat |
chatglm2-6b |
llama-2-13b-chat |
============================================
``bigdl-llm`` quickstart
============================================
- `Windows GPU installation `_
- `Run BigDL-LLM in Text-Generation-WebUI `_
- `Run BigDL-LLM using Docker `_
- `CPU quickstart <#cpu-quickstart>`_
- `GPU quickstart <#gpu-quickstart>`_
--------------------------------------------
CPU Quickstart
--------------------------------------------
You may install ``bigdl-llm`` on Intel CPU as follows as follows:
.. note::
See the `CPU installation guide `_ for more details.
.. code-block:: console
pip install --pre --upgrade bigdl-llm[all]
.. note::
``bigdl-llm`` has been tested on Python 3.9, 3.10 and 3.11
You can then apply INT4 optimizations to any Hugging Face *Transformers* models as follows.
.. code-block:: python
#load Hugging Face Transformers model with INT4 optimizations
from bigdl.llm.transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)
#run the optimized model on Intel CPU
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
input_ids = tokenizer.encode(input_str, ...)
output_ids = model.generate(input_ids, ...)
output = tokenizer.batch_decode(output_ids)
--------------------------------------------
GPU Quickstart
--------------------------------------------
You may install ``bigdl-llm`` on Intel GPU as follows as follows:
.. note::
See the `GPU installation guide `_ for more details.
.. code-block:: console
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade bigdl-llm[xpu] -f https://developer.intel.com/ipex-whl-stable-xpu
.. note::
``bigdl-llm`` has been tested on Python 3.9, 3.10 and 3.11
You can then apply INT4 optimizations to any Hugging Face *Transformers* models on Intel GPU as follows.
.. code-block:: python
#load Hugging Face Transformers model with INT4 optimizations
from bigdl.llm.transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)
#run the optimized model on Intel GPU
model = model.to('xpu')
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
input_ids = tokenizer.encode(input_str, ...).to('xpu')
output_ids = model.generate(input_ids, ...)
output = tokenizer.batch_decode(output_ids.cpu())
**For more details, please refer to the bigdl-llm** `Document `_ and `API Doc `_.
------
************************************************
Overview of the complete BigDL project
************************************************
`BigDL `_ seamlessly scales your data analytics & AI applications from laptop to cloud, with the following libraries:
- ``LLM`` **(deprecated; please use** `IPEX-LLM `_ **instead)**: Optimized large language model library for Intel CPU/GPU
- `Orca `_: Distributed Big Data & AI (TF & PyTorch) Pipeline on Spark and Ray
- `Nano `_: Transparent Acceleration of Tensorflow & PyTorch Programs on Intel CPU/GPU
- `DLlib `_: "Equivalent of Spark MLlib" for Deep Learning
- `Chronos `_: Scalable Time Series Analysis using AutoML
- `Friesian `_: End-to-End Recommendation Systems
- `PPML `_: Secure Big Data and AI (with SGX Hardware Security)
------
************************************************
Choosing the right BigDL library
************************************************
.. graphviz::
digraph BigDLDecisionTree {
graph [pad=0.1 ranksep=0.3 tooltip=" "]
node [color="#0171c3" shape=box fontname="Arial" fontsize=14 tooltip=" "]
edge [tooltip=" "]
Feature1 [label="Hardware Secured Big Data & AI?"]
Feature2 [label="Python vs. Scala/Java?"]
Feature3 [label="What type of application?"]
Feature4 [label="Domain?"]
LLM[href="https://github.com/intel-analytics/ipex-llm" target="_blank" target="_blank" style="rounded,filled" fontcolor="#ffffff" tooltip="Go to BigDL-LLM document"]
Orca[href="../doc/Orca/index.html" target="_blank" target="_blank" style="rounded,filled" fontcolor="#ffffff" tooltip="Go to BigDL-Orca document"]
Nano[href="../doc/Nano/index.html" target="_blank" target="_blank" style="rounded,filled" fontcolor="#ffffff" tooltip="Go to BigDL-Nano document"]
DLlib1[label="DLlib" href="../doc/DLlib/index.html" target="_blank" style="rounded,filled" fontcolor="#ffffff" tooltip="Go to BigDL-DLlib document"]
DLlib2[label="DLlib" href="../doc/DLlib/index.html" target="_blank" style="rounded,filled" fontcolor="#ffffff" tooltip="Go to BigDL-DLlib document"]
Chronos[href="../doc/Chronos/index.html" target="_blank" style="rounded,filled" fontcolor="#ffffff" tooltip="Go to BigDL-Chronos document"]
Friesian[href="../doc/Friesian/index.html" target="_blank" style="rounded,filled" fontcolor="#ffffff" tooltip="Go to BigDL-Friesian document"]
PPML[href="../doc/PPML/index.html" target="_blank" style="rounded,filled" fontcolor="#ffffff" tooltip="Go to BigDL-PPML document"]
ArrowLabel1[label="No" fontsize=12 width=0.1 height=0.1 style=filled color="#c9c9c9"]
ArrowLabel2[label="Yes" fontsize=12 width=0.1 height=0.1 style=filled color="#c9c9c9"]
ArrowLabel3[label="Python" fontsize=12 width=0.1 height=0.1 style=filled color="#c9c9c9"]
ArrowLabel4[label="Scala/Java" fontsize=12 width=0.1 height=0.1 style=filled color="#c9c9c9"]
ArrowLabel5[label="Large Language Model" fontsize=12 width=0.1 height=0.1 style=filled color="#c9c9c9"]
ArrowLabel6[label="Big Data + \n AI (TF/PyTorch)" fontsize=12 width=0.1 height=0.1 style=filled color="#c9c9c9"]
ArrowLabel7[label="Accelerate \n TensorFlow / PyTorch" fontsize=12 width=0.1 height=0.1 style=filled color="#c9c9c9"]
ArrowLabel8[label="DL for Spark MLlib" fontsize=12 width=0.1 height=0.1 style=filled color="#c9c9c9"]
ArrowLabel9[label="High Level App Framework" fontsize=12 width=0.1 height=0.1 style=filled color="#c9c9c9"]
ArrowLabel10[label="Time Series" fontsize=12 width=0.1 height=0.1 style=filled color="#c9c9c9"]
ArrowLabel11[label="Recommender System" fontsize=12 width=0.1 height=0.1 style=filled color="#c9c9c9"]
Feature1 -> ArrowLabel1[dir=none]
ArrowLabel1 -> Feature2
Feature1 -> ArrowLabel2[dir=none]
ArrowLabel2 -> PPML
Feature2 -> ArrowLabel3[dir=none]
ArrowLabel3 -> Feature3
Feature2 -> ArrowLabel4[dir=none]
ArrowLabel4 -> DLlib1
Feature3 -> ArrowLabel5[dir=none]
ArrowLabel5 -> LLM
Feature3 -> ArrowLabel6[dir=none]
ArrowLabel6 -> Orca
Feature3 -> ArrowLabel7[dir=none]
ArrowLabel7 -> Nano
Feature3 -> ArrowLabel8[dir=none]
ArrowLabel8 -> DLlib2
Feature3 -> ArrowLabel9[dir=none]
ArrowLabel9 -> Feature4
Feature4 -> ArrowLabel10[dir=none]
ArrowLabel10 -> Chronos
Feature4 -> ArrowLabel11[dir=none]
ArrowLabel11 -> Friesian
}
------
.. raw:: html
Performance varies by use, configuration and other factors. bigdl-llm may not optimize to the same degree for non-Intel products. Learn more at www.Intel.com/PerformanceIndex.